
[toc]
Introduction
Companies such as F5, A10, and Netscaler (owned by Citrix) have built their respective businesses on the need for load balancing devices in the data center and other parts of the network. While these devices can make the sharing of the load of incoming service connections (eg: HTTP, DNS, etc) very easy, they also come with a sometimes exceptional cost. Further, they centralize incoming connections to a few devices first, which can, in effect, act as a funnel or a bottleneck. This document will explain an alternative to using physical or logical load balancers by pushing BGP routing down to the individual servers.
Load Balancer: Definition
Let me define what I mean by the phrase “load balancer” first: Any physical or logical (eg: VM) device that presents a single IP address for a service. Once it receives connections for that service, it sends the connection to one of a number of servers. For example, a load balancer can present IP address 1.2.3.4 as a web server to the Internet. This load balancer also has a collection of web servers behind it, all IP addressed out of 172.16.0.10 – 172.16.0.20. When a client on the Internet connections to port 80 or 443 on IP 1.2.3.4, the load balancer will use a configured load balancing algorithm to decide which of the servers in the 172.16.0.[10-20] range to send the connection to, and do so. The server will answer the incoming connection, service it, and all of that will be completely transparent to the end user on the Internet. All they’ll know is they’re connection a web server with the IP address of 1.2.3.4.
All the while, the load balancer is doing constant health checking of each of those real servers. If a server doesn’t respond appropriately to the health checking, the load balancer will mark it as “bad” and take it out of the pool of available resources.
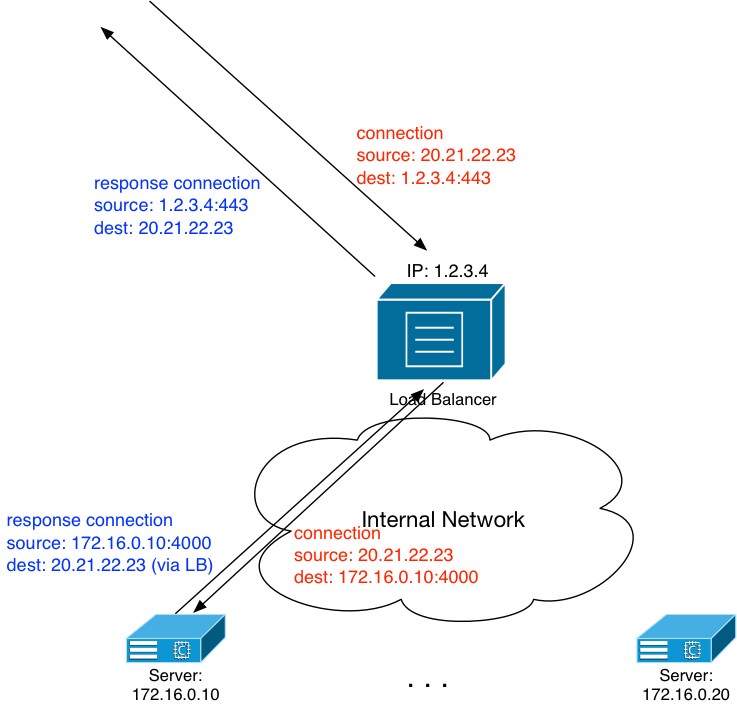
In its simplest form, the load balancer is performing a NAT for the incoming connections, as you can see from the above diagram. The client in this example at IP 20.21.22.23 doesn’t have any idea they’re actually getting content from a server with the IP of 172.16.0.10.
What’s The Problem?
The opening image of this document will make it seem like I hate load balancers. Nothing could be further from the truth. As a (very) young network engineer back at AOL, load balancers made it possible for me to solve interesting problems that we faced at that company. Load balancers from the likes of Foundry provided us with ways to handle the massive number of incoming SMTP connections, for example; far more than most folks today realize. They fronted the login for AIM; do you know the (in)famous login.oscar.aol.com server that’s configured into just about every AIM client in existence? Those connections were handled by load balancers; so many per second, in fact, that we broke a lot of LBs (and even some LB records) and had to push for different technologies on the load balancers to make them handle the load.
But they did.
I’m not anti-LB; rather I’d prefer to use the appropriate solutions in the appropriate places. And I believe that today, with the software we have freely available to us, we can do a better job and do it for a lot less money. Load balancers do cost money; they can cost a lot of money in some cases, and the more connections per second or bits per second that they can service, the higher the price generally goes. This price included capital expenditures (CapEx, or purchasing a “thing”) and operating expenditures (OpEx, or purchasing an ongoing service .. think: support). From a network design, they’re a blocker; a gateway that can rapidly turn into a bottleneck if you have too many requests per second or bits per second flowing through them. By their design, they’re not as distributed as servers can be. You generally don’t buy N load balancers for your N servers. You buy something significantly less than N LBs, which means they can’t be spread out as much. This simplifies management, but centralizes the incoming, and in most cases outgoing connections.
Let’s do it differently, and use some freely available software to do it.
Routing On The Server
Quick Pre-Editorial
The network engineers reading this are about to shift uncomfortably in their seats. “Routing on the server?! No way! Server guys don’t know anything about routing!” Yep, I’ve heard it before. I may have even said it before, many years ago. But ultimately: get over yourselves. That’s as simple a message as I can say. As a network engineer, you know full well that you can put up near-perfect guard rails to prevent any badness from actually happening. You can stop your network from accepting a route from a server that it has no right to announce; think: 0.0.0.0/0, for instance. Trust that your server guys and gals don’t want to bring the network down any more than you want them to do so, and then: get over yourselves.
The Basic Idea: Anycast
Anycast: the practice of announcing the same prefix from multiple sources to distribute the incoming load for those prefixes. The prefixes can be larger network blocks or something small like a /32. We’re going to make use of anycast with this solution. Each server will peer via EBGP with its upstream leaf, and announce the /32 of a service to that leaf. The leaf will then announce that /32 up to its upstream spine. The spines will ECMP the incoming connections for that /32 to each of the leaf nodes announcing it. The leaf nodes will do the same towards each of the servers that are announcing the /32.
Basically: we’re using the ECMP capabilities of BGP to do load balancing.
The Network
I’ve used and re-used this image or images like it throughout my blog. But here it is again:
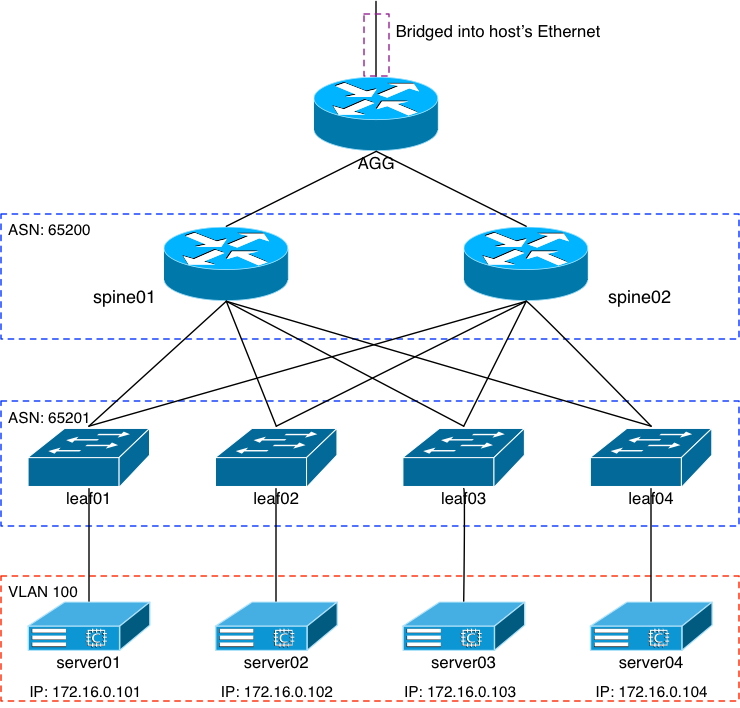
I’ll list out a few important differences in the build since my last entry which involved getting Cumulus and Arista’s vEOS working together.
- The vEOS spines are gone. They worked with EVPN just fine, but the vEOS data plane is very slow. On the order of +80ms of latency slow.
- The server VMs are now FreeBSD. They’re tiny, 4GB images that I built myself using FreeBSD 12.0
- I added another VM, this time connected to leaf04.
Otherwise everything is the same. VLAN100 is being virtually spanned across the spines and leaf nodes via VXLAN, using Cumulus’ excellent EVPN control plane. Each server VM is identical and they each get their identity from an off-net DHCP server.
Free Range Routing
It was through my learning about Cumulus that I became aware of Free Range Routing or FRR. It’s what Cumulus uses for all of the L3 control plane decision making in their operating system. It has its roots in the Quagga project; you’ll see mentions of “Zebra”, which is the ancestor of Quagga, all over the FRR software distributions, man pages, etc. The question is: has someone built FRR for FreeBSD?
server01# pkg search frr frr3-3.0.4 IP routing protocol suite including BGP, IS-IS, OSPF and RIP frr4-4.0.1 IP routing protocol suite including BGP, IS-IS, OSPF and RIP frr5-5.0.2 IP routing protocol suite including BGP, IS-IS, OSPF and RIP frr6-6.0.2_1 IP routing protocol suite including BGP, IS-IS, OSPF and RIP
Why yes, yes they have. That will make installing it a lot easier. I used FreeBSD’s pkg command to install version 6 of FRR, along with the Apache 2.4 web server.
BGP Unnumbered
I’ve made it clear that I’m a HUGE fan of FRR’s BGP unnumbered solution, and I wanted to use it here, as well. To do that properly but still allow me a way to ssh into the server if routing broke or needed restarting, I decided the FreeBSD VMs would get a second interface between themselves and their upstream leaf. It’s simple enough to do within the bhyve infrastructure I’ve built: I added 4 more virtual switches named lf01-srv01a to lf04-srv04a:
# vm switch list NAME TYPE IFACE ADDRESS PRIVATE MTU VLAN PORTS [clip] lf01-srv01a standard vm-lf01-srv01a - no - - - lf02-srv02a standard vm-lf02-srv02a - no - - - lf03-srv03a standard vm-lf03-srv03a - no - - - lf04-srv04a standard vm-lf04-srv04a - no - - -
I edited the config files for each of the eight VMs in question: leaf01-04 and server01-04. After restarting each VM, each leaf and server had 2 connections between them. The server VMs still DHCP’d out to get an IP assigned to the first interface, but the second one received no IP at all:
server01# ifconfig -a em0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500 options=81009b<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,VLAN_HWCSUM,VLAN_HWFILTER> ether 58:9c:fc:00:5e:43 inet6 fe80::5a9c:fcff:fe00:5e43%em0 prefixlen 64 scopeid 0x1 inet 172.16.0.101 netmask 0xffffff00 broadcast 172.16.0.255 media: Ethernet autoselect (1000baseT <full-duplex>) status: active nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL> em1: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500 options=81009b<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,VLAN_HWCSUM,VLAN_HWFILTER> ether 58:9c:fc:04:71:4e inet6 fe80::5a9c:fcff:fe04:714e%em1 prefixlen 64 scopeid 0x2 media: Ethernet autoselect (1000baseT <full-duplex>) status: active nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
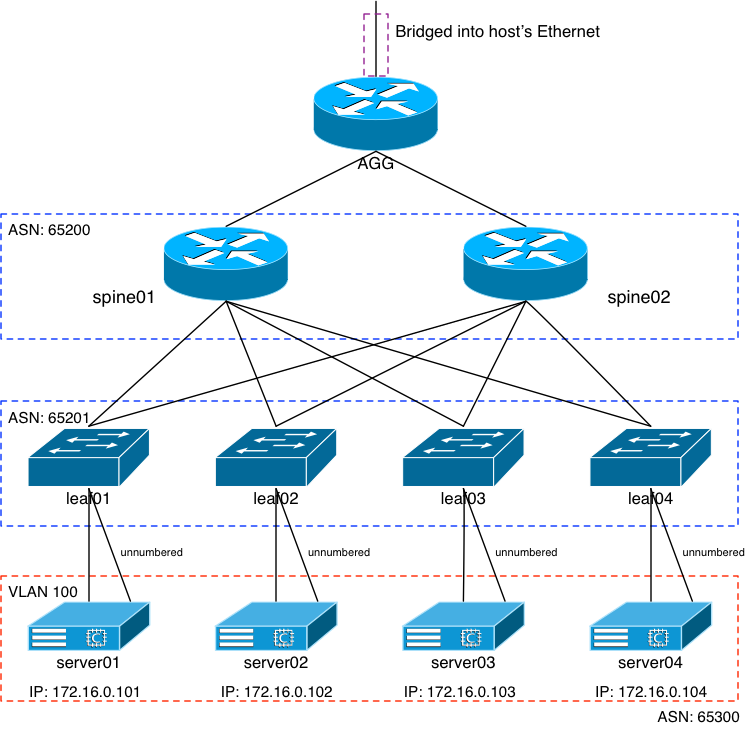
Configuring: The Servers
The Route Control Plane
As you can see from the previous diagram, I decided to use ASN: 65300 for the servers. With that, the FreeBSD pkg for FRR installs the config files in /usr/local/etc/frr. A bunch of sample config files exist in this directory, but we’re going to ignore them all. We’ll be running zebrad, bgpd, and bfdd; each will need a config file. Fortunately, it’s only the bgpd that needs actual configuration; the other two files can be 0 length.
server01# cd /usr/local/etc/frr server01# touch bgpd.conf bfdd.conf zebra.conf
None of this is terribly difficult to do. If you’ve followed along with the Cumulus VX configurations, or you’ve done any sort of work with IOS, EOS, etc, then it’s simple. My bgpd.conf for all four servers looks like this:
router bgp 65300 neighbor leaf peer-group neighbor leaf remote-as external neighbor leaf bfd neighbor em1 interface peer-group leaf address-family ipv4 unicast redistribute connected exit-address-family
There’s nothing in the config file that’s server-specific. No IP addresses or anything. Simply put: the daemon will attempt to EBGP-peer with whatever is connected to interface em1, and then announce all of the directly-connected interface routes to that new peer.
The Anycast IP
Before we work on the leaf nodes, we need our anycast IP. Remember that I’m redistributing directly-connected interfaces, so it makes sense to attach that IP (I’ve chosen 172.20.0.1/32) to an interface. The challenge is: which interface? We have to be careful here; if we attach that IP to an existing broadcast domain, the other servers doing the same thing will all see “duplicate IP addresses”
May 16 17:57:57 server01 kernel: arp: 58:9c:fc:0d:31:23 is using my IP address 172.20.0.1 on em0! May 16 17:57:58 server01 kernel: arp: 58:9c:fc:08:d4:2e is using my IP address 172.20.0.1 on em0! May 16 17:57:59 server01 kernel: arp: 58:9c:fc:0d:31:23 is using my IP address 172.20.0.1 on em0! May 16 17:58:00 server01 syslogd: last message repeated 1 times
The answer, of course, is a loopback interface. Those never answer ARP requests. We can add the IP as an alias to the FreeBSD lo0, or just create another loopback. I decided on the latter, and I’ll explain why in a moment. In the /etc/rc.conf of the server:
cloned_interfaces="lo1" ifconfig_lo1="inet 172.20.0.1/32"
And without rebooting the server, we can just do this:
server01# ifconfig lo1 create server01# ifconfig lo1 inet 172.20.0.1/32 up server01# ifconfig lo1 lo1: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> metric 0 mtu 16384 options=680003<RXCSUM,TXCSUM,LINKSTATE,RXCSUM_IPV6,TXCSUM_IPV6> inet 172.20.0.1 netmask 0xffffffff groups: lo nd6 options=29<PERFORMNUD,IFDISABLED,AUTO_LINKLOCAL>
Voila: we have 172.20.0.1/32 as an IP on each VM, and it’ll never answer an ARP request.
Configuring: The Leaf Nodes
Configuring the leaf nodes will be handled by the Ansible infrastructure that I’ve built over the course of the last several blog entries. Again, this is incredibly simple to do because I’ve chosen no device-specific IPs, names, etc. It’s all very generic and the peering will just come right up.
New Anycast YAML File
In the root of my Ansible directory, I whipped up a new YAML file called anycast.yaml:
- hosts: leaf become: true roles: - interfaces - bgp
The reason for that for this specific change, I wanted the ansible process to go a bit quicker (I’m impatient, after all!) so I’m going to have it focus on interfaces and BGP.
Interfaces
---
- name: Configure swp interfaces
nclu:
commands:
- add interface swp1-6
All I did here was change the “swp1-5” to “swp1-6”. Done.
BGP
---
- name: BGP with EVPN
nclu:
commands:
- add routing prefix-list ipv4 anycast seq 5 permit 172.20.0.1/32
- add bgp neighbor anycast peer-group
- add bgp neighbor anycast remote-as external
- add bgp neighbor anycast bfd
- add bgp neighbor swp6 interface peer-group anycast
- add bgp ipv4 unicast neighbor anycast prefix-list anycast in
The changes here are also pretty simple:
- Create a prefix-list matching on the 172.20.0.1 anycast IP
- Create a new anycast peer-group
- Peer on interface swp6, and put that peer in the anycast peer-group
- Make sure the new prefix-list is applied
From my laptop, I fired this command off:
$ ansible-playbook anycast.yaml -i hosts -K
Quick Check
Do we have a peer and a route? Let’s check on leaf01:
root@leaf01:mgmt-vrf:/home/jvp# net show bgp sum show bgp ipv4 unicast summary ============================= BGP router identifier 10.100.0.3, local AS number 65201 vrf-id 0 BGP table version 39 RIB entries 43, using 6536 bytes of memory Peers 7, using 135 KiB of memory Peer groups 3, using 192 bytes of memory Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd server01.private.lateapex.net(swp6) 4 65300 29146 29440 0 0 0 1d00h31m 1 [clip] root@leaf01:mgmt-vrf:/home/jvp# net show route 172.20.0.1/32 RIB entry for 172.20.0.1/32 =========================== Routing entry for 172.20.0.1/32 Known via "bgp", distance 20, metric 1, best Last update 1d00h32m ago * fe80::5a9c:fcff:fe04:714e, via swp6 FIB entry for 172.20.0.1/32 =========================== 172.20.0.1 via 169.254.0.1 dev swp6 proto bgp metric 20 onlink
Looks like it. What about the spines? They should see four entries for that prefix, since they have four leaf nodes:
root@spine01:mgmt-vrf:/home/jvp# net show route 172.20.0.1/32 RIB entry for 172.20.0.1/32 =========================== Routing entry for 172.20.0.1/32 Known via "bgp", distance 20, metric 0, best Last update 1d00h31m ago * fe80::5a9c:fcff:fe01:5381, via swp3 * fe80::5a9c:fcff:fe0e:b3f9, via swp6 * fe80::5a9c:fcff:fe02:afcd, via swp5 * fe80::5a9c:fcff:fe05:17d7, via swp4 FIB entry for 172.20.0.1/32 =========================== 172.20.0.1 proto bgp metric 20 nexthop via 169.254.0.1 dev swp3 weight 1 onlink nexthop via 169.254.0.1 dev swp6 weight 1 onlink nexthop via 169.254.0.1 dev swp5 weight 1 onlink nexthop via 169.254.0.1 dev swp4 weight 1 onlink
So far, so good. Can I get to the 172.20.0.1 IP with a simple ping from my laptop?
$ traceroute -n 172.20.0.1 traceroute to 172.20.0.1 (172.20.0.1), 64 hops max, 52 byte packets 1 192.168.10.254 0.535 ms 0.238 ms 0.244 ms 2 10.200.0.2 0.906 ms 0.990 ms 0.994 ms 3 10.0.3.1 2.235 ms 2.495 ms 3.072 ms 4 10.100.0.3 2.293 ms 2.399 ms 2.226 ms 5 172.20.0.1 2.042 ms 2.234 ms 2.393 ms $ ping 172.20.0.1 PING 172.20.0.1 (172.20.0.1): 56 data bytes 64 bytes from 172.20.0.1: icmp_seq=0 ttl=60 time=2.127 ms 64 bytes from 172.20.0.1: icmp_seq=1 ttl=60 time=2.256 ms 64 bytes from 172.20.0.1: icmp_seq=2 ttl=60 time=2.242 ms 64 bytes from 172.20.0.1: icmp_seq=3 ttl=60 time=1.628 ms ^C --- 172.20.0.1 ping statistics --- 4 packets transmitted, 4 packets received, 0.0% packet loss round-trip min/avg/max/stddev = 1.628/2.063/2.256/0.256 ms
I can.
Apache Configuration
I’m not going to spend a bunch of space talking about configuring an Apache server. There are tomes written about it, all available on the ‘net somewhere. What I will explain is what I did for this specific experiment.
By default, FreeBSD’s Apache install has its base index.html in /usr/local/www/apache24/data. That file is the only part of this entire process that I made machine-specific, and I did so for a reason:
server01# cat /usr/local/www/apache24/data/index.html <html><body> <h1>It works!</h1> server01 </body></html>
As you can see, I added the server’s hostname to the text output for each. That way when I connect to the Apache server and pull the index file, I’ll know which actual VM I connected to.
That’s it.
Checking Our Apache Work
A random check from my laptop:
$ telnet 172.20.0.1 80 Trying 172.20.0.1... Connected to 172.20.0.1. Escape character is '^]'. GET /index.html HTTP/1.0 HTTP/1.1 200 OK Date: Sat, 18 May 2019 18:34:04 GMT Server: Apache/2.4.39 (FreeBSD) Last-Modified: Thu, 16 May 2019 17:24:42 GMT ETag: "39-589048aa64786" Accept-Ranges: bytes Content-Length: 57 Connection: close Content-Type: text/html <html><body> <h1>It works!</h1> server01 </body></html> Connection closed by foreign host.
You can see at the bottom that I connected to server01. How about from the hypervisor that the entire system is running on?
$ telnet 172.20.0.1 80 Trying 172.20.0.1... Connected to 172.20.0.1. Escape character is '^]'. GET /index.html HTTP/1.0 HTTP/1.1 200 OK Date: Sat, 18 May 2019 18:35:29 GMT Server: Apache/2.4.39 (FreeBSD) Last-Modified: Thu, 16 May 2019 20:20:02 GMT ETag: "3a-58906fdadd663" Accept-Ranges: bytes Content-Length: 58 Connection: close Content-Type: text/html <html><body> <h1>It works!</h1> server02 </body></html> Connection closed by foreign host.
Looks like server02 was handed the connection. From my fileserver?
$ telnet 172.20.0.1 80 Trying 172.20.0.1... Connected to 172.20.0.1. Escape character is '^]'. GET /index.html HTTP/1.0 HTTP/1.1 200 OK Date: Sat, 18 May 2019 18:36:25 GMT Server: Apache/2.4.39 (FreeBSD) Last-Modified: Thu, 16 May 2019 20:20:02 GMT ETag: "3a-58906fdadd663" Accept-Ranges: bytes Content-Length: 58 Connection: close Content-Type: text/html <html><body> <h1>It works!</h1> server02 </body></html> Connection closed by foreign host.
Server02 again. How about from my network’s main router?
$ telnet 172.20.0.1 80 Trying 172.20.0.1... Connected to 172.20.0.1. Escape character is '^]'. GET /index.html HTTP/1.0 HTTP/1.1 200 OK Date: Sat, 18 May 2019 18:37:34 GMT Server: Apache/2.4.39 (FreeBSD) Last-Modified: Thu, 16 May 2019 20:22:03 GMT ETag: "3a-5890704ebb0c0" Accept-Ranges: bytes Content-Length: 58 Connection: close Content-Type: text/html <html><body> <h1>It works!</h1> server03 </body></html> Connection closed by foreign host.
Server03 this time.
Hopefully it’s obvious that the load is being spread across the various servers. The challenge of course is that with a fairly limited number of source IPs from my home network, the spread won’t be as even. But if this were a service you were putting up for the Internet at large, the distribution of load would be a lot more even.
Health Checking
One job of a load balancer is the constantly check the health of the real servers it’s in front of. If it finds a problem with one of the servers, it should mark that server as “down” and stop sending new connections to it until that server passes health checking again. There are a bunch of ways to do health checking from simple pings (L3), to connecting to the server and making sure it accepts the connections (L4), all the way to performing a specific action once connected and comparing that result with a known good one (L7).
However, our network gear (spines and leaf nodes) is what’s providing the load balancing, and they’re not really set up to do intelligent health checking. In fact, we really don’t want them to be. They should be as passive a participant in this whole thing as possible, other than carrying the prefixes.
That leaves us to doing the health checking on the server itself. And here’s where my blog entry will sort of fail. It’s going to require that a smart person who can write good code (I can’t) whip something up that can sit in the background and check the status of the local Apache service. It can do simple L4 checks by connecting to port 80, or it can do something more intelligent by trying to pull an HTML file from the server once connected. A failure of either of these should result in the server being pulled out of rotation.
But how? Well, I’m not a good coder, but I am a good infrastructure planner. Remember that loopback interface we created earlier? What if we delete it when the Apache server fails its local health checking? In fact, it makes sense to not have the interface’s creation in the /etc/rc.conf file, but instead have the health-checking script create it when the VM first boots up and is ready for connections.
I’ll show you what I mean via the command line. We’ll take server01 again; let’s imagine the health-checking script that some smarter person wrote has decided it’s not answering properly. It could then issue this command:
ifconfig lo1 destroy
Did it work? Well let’s check all the way up at the spines, which used to have four entries for that prefix:
root@spine01:mgmt-vrf:/home/jvp# net show route 172.20.0.1/32 RIB entry for 172.20.0.1/32 =========================== Routing entry for 172.20.0.1/32 Known via "bgp", distance 20, metric 0, best Last update 00:00:40 ago * fe80::5a9c:fcff:fe05:17d7, via swp4 * fe80::5a9c:fcff:fe0e:b3f9, via swp6 * fe80::5a9c:fcff:fe02:afcd, via swp5 FIB entry for 172.20.0.1/32 =========================== 172.20.0.1 proto bgp metric 20 nexthop via 169.254.0.1 dev swp4 weight 1 onlink nexthop via 169.254.0.1 dev swp6 weight 1 onlink nexthop via 169.254.0.1 dev swp5 weight 1 onlink
Three entries.
And when the script decides the Apache server is healthy again:
ifconfig lo1 create inet 172.20.0.1/32 up
And:
root@spine01:mgmt-vrf:/home/jvp# net show route 172.20.0.1/32 RIB entry for 172.20.0.1/32 =========================== Routing entry for 172.20.0.1/32 Known via "bgp", distance 20, metric 0, best Last update 00:00:09 ago * fe80::5a9c:fcff:fe05:17d7, via swp4 * fe80::5a9c:fcff:fe01:5381, via swp3 * fe80::5a9c:fcff:fe0e:b3f9, via swp6 * fe80::5a9c:fcff:fe02:afcd, via swp5 FIB entry for 172.20.0.1/32 =========================== 172.20.0.1 proto bgp metric 20 nexthop via 169.254.0.1 dev swp4 weight 1 onlink nexthop via 169.254.0.1 dev swp3 weight 1 onlink nexthop via 169.254.0.1 dev swp6 weight 1 onlink nexthop via 169.254.0.1 dev swp5 weight 1 onlink
…we have four entries again.
The important thing to keep in mind here is that: at no time did I touch the routing configuration of the server, the leaf node, nor the spines. This was all handled by deleting and re-creating a loopback interface on the server, and that’s it.
Important Note: Managing Server Load
One of the challenges I’m facing here is that my hypervisor is doing a bunch of stuff, so running a pile of VMs on it can start to slow it down a bit. It’s why I only have four VMs, each attached to one of four leaf nodes. But importantly: each leaf node only has one entry for that anycast IP. So when the server goes away, the leaf node pulls the route from the spines. That’s why the previous health checking showed up all the way at the spine.
In reality, you’d have a bunch more servers attached to each leaf node. In the case of this network, for instance, you might have four or eight servers connected to each leaf node. Each spine would still only see four entries for the prefix in question. Each leaf, however, would see four or eight entries. And when one of the VMs died, the spines would never know; they’d continue to see four entries from the leaf nodes. This can potentially cause an issue because each leaf is seen as an equal path from the spines’ perspective, even if the leaf only has one of its eight servers running properly. If that one server can’t take on the load from the other seven servers, you could run into connection problems and unhappy clients.
Summary: Really? No Load Balancers?
No, not really. You’ll need and want the extra processing power of a load balancer if your servers are doing sticky (cookie-based) HTTP(S), for instance. The load balancing provided by routing is purely based on source and destination IPs (and ports). It doesn’t care about what’s being carried within that communication whatsoever. It’s not watching cookie transactions, or anything above L4. So if you’ve got services such as that, then you’ll want to utilize a load balancer solution that’s more complex than simple routing.
Where solutions like this work are simple connections. Think: DNS, NTP, et al. Think: quick-and-dirty websites that don’t exchange cookies; they’re just front ends for something. Your front-end SMTP exchanges are another example. Route-based load balancing will easily support those types of transactions. But anything more complex that requires some sort of persistence isn’t a good candidate for this solution.
1 thought on “Load Balancers Be Damned: Routing On The Server”