[toc]
Introduction
In yesterday’s Load Balancers Be Damned post, I demonstrated how adding Free Range Routing to servers could provide a way to do anycast load balancing without the need for expensive load balancers in some cases. What I didn’t really demonstrate well was the ECMP capabilities of the leaf nodes. I also punted on the required local health checking script because I’m not the best script-writer in the world. This document will attempt to answer both of those.
Leaf-Level ECMP
My lab is fairly simple: each leaf node has a single server connected to it. As I explained previously, I didn’t want to spin up a ton of new VMs just to demonstrate the leaf nodes ECMP’ing the incoming HTTP requests. As it turns out, there’s another way to do it using the same number of leaf nodes and VMs:
Inter-connect all VMs to all leaf nodes.
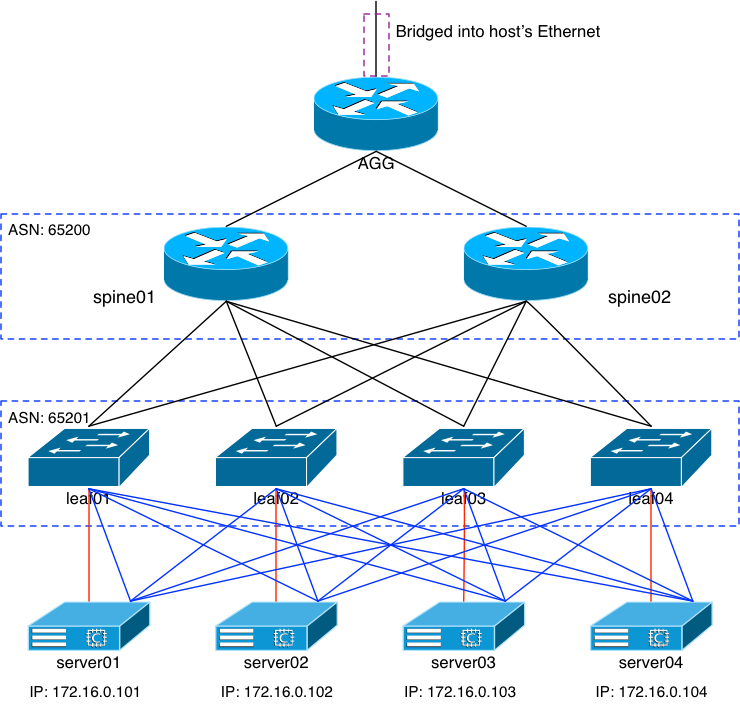
This is, far and away, a stupid idea. Please DON’T do something like this in production. I only did this to demonstrate the load balancing potential of the leaf nodes, not because I actually think it’s a good idea. It isn’t. I even named the diagram “stupid”.
Each red line is the VM’s primary Ethernet interface in VLAN100. The other four blue interfaces are all unnumbered and are used for the EBGP peering with the four leaf nodes. I’m not going to get into the details of the configuration because it should be evident what I needed to change if you read yesterday’s post. But to demonstrate the results, we’ll look at leaf01 and ask it:
root@leaf01:mgmt-vrf:/home/jvp# net show route 172.20.0.1/32 RIB entry for 172.20.0.1/32 =========================== Routing entry for 172.20.0.1/32 Known via "bgp", distance 20, metric 1, best Last update 00:00:10 ago * fe80::5a9c:fcff:fe08:499d, via swp8 * fe80::5a9c:fcff:fe0b:628f, via swp9 * fe80::5a9c:fcff:fe04:714e, via swp6 * fe80::5a9c:fcff:fe0b:b9d8, via swp7 FIB entry for 172.20.0.1/32 =========================== 172.20.0.1 proto bgp metric 20 nexthop via 169.254.0.1 dev swp8 weight 1 onlink nexthop via 169.254.0.1 dev swp9 weight 1 onlink nexthop via 169.254.0.1 dev swp6 weight 1 onlink nexthop via 169.254.0.1 dev swp7 weight 1 onlink
It has four entries for 172.20.0.1/32 because there are four servers.
What about the spines?
root@spine01:mgmt-vrf:/home/jvp# net show route 172.20.0.1/32 RIB entry for 172.20.0.1/32 =========================== Routing entry for 172.20.0.1/32 Known via "bgp", distance 20, metric 0, best Last update 08:07:17 ago * fe80::5a9c:fcff:fe01:5381, via swp3 * fe80::5a9c:fcff:fe0e:b3f9, via swp6 * fe80::5a9c:fcff:fe05:17d7, via swp4 * fe80::5a9c:fcff:fe02:afcd, via swp5 FIB entry for 172.20.0.1/32 =========================== 172.20.0.1 proto bgp metric 20 nexthop via 169.254.0.1 dev swp3 weight 1 onlink nexthop via 169.254.0.1 dev swp6 weight 1 onlink nexthop via 169.254.0.1 dev swp4 weight 1 onlink nexthop via 169.254.0.1 dev swp5 weight 1 onlink
Four entries because there are four leaf nodes.
What if I take the routing down on one of the servers? Well, let’s look at leaf01 again:
root@leaf01:mgmt-vrf:/home/jvp# net show route 172.20.0.1/32 RIB entry for 172.20.0.1/32 =========================== Routing entry for 172.20.0.1/32 Known via "bgp", distance 20, metric 1, best Last update 00:00:01 ago * fe80::5a9c:fcff:fe08:499d, via swp8 * fe80::5a9c:fcff:fe0b:628f, via swp9 * fe80::5a9c:fcff:fe0b:b9d8, via swp7 FIB entry for 172.20.0.1/32 =========================== 172.20.0.1 proto bgp metric 20 nexthop via 169.254.0.1 dev swp8 weight 1 onlink nexthop via 169.254.0.1 dev swp9 weight 1 onlink nexthop via 169.254.0.1 dev swp7 weight 1 onlink
Three entries, as expected.
And the spine?
root@spine01:mgmt-vrf:/home/jvp# net show route 172.20.0.1/32 RIB entry for 172.20.0.1/32 =========================== Routing entry for 172.20.0.1/32 Known via "bgp", distance 20, metric 0, best Last update 08:09:58 ago * fe80::5a9c:fcff:fe01:5381, via swp3 * fe80::5a9c:fcff:fe0e:b3f9, via swp6 * fe80::5a9c:fcff:fe05:17d7, via swp4 * fe80::5a9c:fcff:fe02:afcd, via swp5 FIB entry for 172.20.0.1/32 =========================== 172.20.0.1 proto bgp metric 20 nexthop via 169.254.0.1 dev swp3 weight 1 onlink nexthop via 169.254.0.1 dev swp6 weight 1 onlink nexthop via 169.254.0.1 dev swp4 weight 1 onlink nexthop via 169.254.0.1 dev swp5 weight 1 onlink
It still has four entries as should be expected. Each leaf node still has at least one valid entry for that prefix, so they’ll all announce it. The spine has no idea that one of the servers is down.
Hopefully it’s pretty clear that the spines will ECMP across the leaf nodes, and the leaf nodes will then ECMP across their connected servers.
Health Checking
I’m going to put the script that I ended up with right here, and then I’ll describe my thought processes on it all:
#!/usr/local/bin/python
# Loops forever, at an interval defined below, checking the health of the local
# Apache server. If the server is up, the route will be injected. Otherwise
# it'll be withdrawn from BGP.
#
# Best to start this with nohup.
# nohup anycast_healthck.py &
#
import urllib3
import socket
import subprocess
import time
# Some variables we'll be using
server = "172.20.0.1" # server's IP
httpport = "80" # server's port (80 or 443)
index = "/index.html" # file we'll grab during the health check
url = "http://" + server + index # URL we'll be grabbing to health check
service = "down" # we'll start assuming service is down
hc_interval = 5 # health check interval, in seconds
route_add = "/usr/local/bin/vtysh -c 'enable' -c 'config term' -c 'router bgp 65300' -c 'network 172.20.0.1/32' -c 'exit' -c 'exit'"
route_del = "/usr/local/bin/vtysh -c 'enable' -c 'config term' -c 'router bgp 65300' -c 'no network 172.20.0.1/32' -c 'exit' -c 'exit'"
#
# isOpen(IP_addr, Port)
#
# Checks to see if it can open a TCP connection to IP:Port.
# Returns True if it can, False otherwise
def isOpen(ip, port):
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
try:
s.connect((ip, int(port)))
s.shutdown(2)
return True
except:
return False
# Use our isOpen() function along with a URL request to see if:
# A) the server is accepting connections on its HTTP port
# AND
# B) we can pull the HTML file successfully.
#
# A success on both will mean the server is healthy.
while(not time.sleep(hc_interval)):
if isOpen(server, httpport) and urllib3.PoolManager().request('GET', url).status == 200:
if service == "down": # We currently think the service is down, so turn it up
subprocess.call(route_add, shell=True)
service = "up"
else:
if service == "up": # We currently think the service is up, so turn it down.
subprocess.call(route_del, shell=True)
service = "down"
Leave Loopback1 Alone
Recall from the previous document that I put interface lo1 in place to serve as a way to start and stop the routing. The idea is that the health checking script that someone smarter than I would write would ifconfig that interface down if the Apache process wasn’t healthy, which would withdraw the route. And then later it would ifconfig the interface back up when healthy, which would inject the route again. But there’s a problem with that approach: the loopback interface had the 172.20.0.1/32 IP configured on it. If it was down, there’d be no way for the health checking script to check it properly to bring it back online. That is unless the script tried to connect to 127.0.0.1 instead, which I wanted to avoid.
Ultimately, I decided to leave loopback1 alone. It’s up and will stay up. I had to figure out a different way to do it.
FRR’s VTYSH To The Rescue
The vtysh command that comes with the frr package is a shell; it looks and feels a lot like Cisco’s IOS or Arista’s EOS. All of the “show” and “config” commands work in it but any changes made in it are only stored in the running daemons’ memory. You still have to write out the changes if you want the same changes to be present the next time the daemons start. In other words: the changes are just runtime.
Hey… that’s perfect! I can make use of that very aspect of vtysh, because it has a “-c” option just like any other shell in Unix. It will run the command that’s passed in with the -c option, and then vtysh will exit out, leaving the changes in (for instance) bgpd’s runtime.
Changes will need to be made to the /usr/local/etc/frr/bgpd.conf file:
router bgp 65300 neighbor leaf peer-group neighbor leaf remote-as external neighbor leaf bfd neighbor em1 interface peer-group leaf neighbor em2 interface peer-group leaf neighbor em3 interface peer-group leaf neighbor em4 interface peer-group leaf
Missing from the file is the redistribution of directly-connected interfaces. When I restart the FRR processes with this change in place, the 172.20.0.1/32 prefix will no longer be announced.
However, if you look at the last section of the script, you’ll see the main loop is doing a subprocess.call. I defined the string variables that I’m sending to that function, up at the top of the script. You’ll see:
route_add = "/usr/local/bin/vtysh -c 'enable' -c 'config term' -c 'router bgp 65300' -c 'network 172.20.0.1/32' -c 'exit' -c 'exit'" route_del = "/usr/local/bin/vtysh -c 'enable' -c 'config term' -c 'router bgp 65300' -c 'no network 172.20.0.1/32' -c 'exit' -c 'exit'"
Basically what they’re doing is telling vtysh to either add the 172.20.0.1/32 prefix to BGP or delete it. And as long as bgpd is running, whatever the last state the health checking script set will remain.
Starting The Script
In the file /etc/rc.local:
nohup /usr/local/bin/anycast_healthchk.py &
It’s run after Apache and FRR are started and, as long as everything is healthy, the prefix will get injected into BGP.
Does It Work?
Short answer: yes, it works fine. But you want the long answer as proof of course. On server01, I’ll shut the Apache server down and then check leaf01 to see if it’s lost one of the routes:
root@leaf01:mgmt-vrf:/home/jvp# net show route 172.20.0.1/32 RIB entry for 172.20.0.1/32 =========================== Routing entry for 172.20.0.1/32 Known via "bgp", distance 20, metric 0, best Last update 00:00:01 ago * fe80::5a9c:fcff:fe08:499d, via swp8 * fe80::5a9c:fcff:fe0b:628f, via swp9 * fe80::5a9c:fcff:fe0b:b9d8, via swp7 FIB entry for 172.20.0.1/32 =========================== 172.20.0.1 proto bgp metric 20 nexthop via 169.254.0.1 dev swp8 weight 1 onlink nexthop via 169.254.0.1 dev swp9 weight 1 onlink nexthop via 169.254.0.1 dev swp7 weight 1 onlink
Sure enough, three entries. Server01’s entry is gone. Let’s turn Apache back up and check again:
root@leaf01:mgmt-vrf:/home/jvp# net show route 172.20.0.1/32 RIB entry for 172.20.0.1/32 =========================== Routing entry for 172.20.0.1/32 Known via "bgp", distance 20, metric 0, best Last update 00:00:00 ago * fe80::5a9c:fcff:fe08:499d, via swp8 * fe80::5a9c:fcff:fe04:714e, via swp6 * fe80::5a9c:fcff:fe0b:628f, via swp9 * fe80::5a9c:fcff:fe0b:b9d8, via swp7 FIB entry for 172.20.0.1/32 =========================== 172.20.0.1 proto bgp metric 20 nexthop via 169.254.0.1 dev swp8 weight 1 onlink nexthop via 169.254.0.1 dev swp6 weight 1 onlink nexthop via 169.254.0.1 dev swp9 weight 1 onlink nexthop via 169.254.0.1 dev swp7 weight 1 onlink
Within a few short seconds, we have four entries again. L4 checking complete. How about L7? We can verify that by making the index.html file unreadable. On server01:
server01# chmod og-r /usr/local/www/apache24/data/index.html
And on the leaf?
root@leaf01:mgmt-vrf:/home/jvp# net show route 172.20.0.1/32 RIB entry for 172.20.0.1/32 =========================== Routing entry for 172.20.0.1/32 Known via "bgp", distance 20, metric 0, best Last update 00:00:06 ago * fe80::5a9c:fcff:fe08:499d, via swp8 * fe80::5a9c:fcff:fe0b:628f, via swp9 * fe80::5a9c:fcff:fe0b:b9d8, via swp7 FIB entry for 172.20.0.1/32 =========================== 172.20.0.1 proto bgp metric 20 nexthop via 169.254.0.1 dev swp8 weight 1 onlink nexthop via 169.254.0.1 dev swp9 weight 1 onlink nexthop via 169.254.0.1 dev swp7 weight 1 onlink
Three entries. Resetting the permissions on the file on server01:
server01# chmod og+r /usr/local/www/apache24/data/index.html
And on the leaf:
root@leaf01:mgmt-vrf:/home/jvp# net show route 172.20.0.1/32 RIB entry for 172.20.0.1/32 =========================== Routing entry for 172.20.0.1/32 Known via "bgp", distance 20, metric 0, best Last update 00:00:09 ago * fe80::5a9c:fcff:fe08:499d, via swp8 * fe80::5a9c:fcff:fe04:714e, via swp6 * fe80::5a9c:fcff:fe0b:628f, via swp9 * fe80::5a9c:fcff:fe0b:b9d8, via swp7 FIB entry for 172.20.0.1/32 =========================== 172.20.0.1 proto bgp metric 20 nexthop via 169.254.0.1 dev swp8 weight 1 onlink nexthop via 169.254.0.1 dev swp6 weight 1 onlink nexthop via 169.254.0.1 dev swp9 weight 1 onlink nexthop via 169.254.0.1 dev swp7 weight 1 onlink
Four entries. L7 health checking works.
Summary
I whipped together what I consider a very stupid network design to demonstrate the fact that the spines will ECMP to the leaf nodes, which will then ECMP to however many servers each has connected to it. Hopefully that was pretty clear, and also clear why the demo is a bad idea. Don’t do that.
Then, with the help of some Googling, I was able to hack together a python script to handle local health checking for the Apache server. It does both L4 and L7 checking, and performs proper Route Health Injection (or withdrawal) based on the health of the Apache server.
And I’m still the worst python coder in existence. So there.
1 thought on “Adding More ECMP and Health Checking To Anycast Lab”